
python爬虫入门——Day09(scrapy中间件详解)
Introduction
中间件是Scrapy里面的一个核心概念。使用中间件可以在爬虫的请求发起之前或者请求返回之后对数据进行定制化修改,从而开发出适应不同情况的爬虫。
分为两大种类:下载器中间件(DownloaderMiddleware)和爬虫中间件(SpiderMiddleware)
通常由于在请求对象和响应对象数据,在下载中间件就能处理好,所以一般不会去使用爬虫中间件。
下载中间件
下载中间件的作用就是:
- 引擎engine将request对象交给下载器之前,会经过下载器中间件;此时,中间件提供了一个方法 process_request,可以对 request对象进行设置随机请求头、IP代理、Cookie等;
- 当下载器完成下载时,获得到 response对象,将它交给引擎engine的过程中,再一次经过 下载器中间件;此时,中间件提供了另一个方法 process_response;可以判断 response对象的状态码,来决定是否将 response提交给引擎。
使用下载器中间件时必须激活这个中间件,方法是在settings.py文件中设置DOWNLOADER_MIDDLEWARES这个字典,格式类似如下:
DOWNLOADERMIDDLEWARES = {
'myproject.middlewares.Custom_A_DownloaderMiddleware': 543,
'myproject.middlewares.Custom_B_DownloaderMiddleware': 643,
'myproject.middlewares.Custom_B_DownloaderMiddleware': None,
}
数字越小,越靠近引擎,数字越大越靠近下载器,所以数字越小的,processrequest()优先处理;数字越大的,process_response()优先处理;若需要关闭某个中间件直接设为None即可
下载中间件主要用到的方法有三个:
process_request:用来处理正常的请求对象的数据,每个request请求通过下载中间件时,该方法被调用。
process_response:用来处理响应对象的数据
process_exception:用来处理抛异常的请求对象的数据
其他的初始化类的对象的方法及打开日志的方法可有可无。
process_request(self,request,spider)
下载器在发送请求之前会执行的,一般可以在这个里面设置随机代理 ip 等
参数: request:发送请求的 request 对象 spider:发送请求的 spider 对象
返回值有可能会返回下面的任何一种:
- 返回
None:如果返回None,Scrapy 将继续处理该request,执行其他中间件中的相应方法,直到合适的下载器处理函数被调用 - 返回
Response对象:Scrapy 将不会调用任何其他的process_request方法,将直接返回这个response对象,已经激活的中间件的 process_response() 方法则会在每个 response 返回时被调用 - 返回
Request对象:Scrapy则停止调用process_request方法并重新调度返回的request。当新返回的request被执行后, 相应地中间件链将会根据下载的response被调用 - 如果其raise一个
IgnoreRequest异常,则安装的下载中间件的process_exception()方法会被调用。
通常返回None较常见,它会继续执行爬虫下去。
process_response(self,request,response,spider)
下载器下载的数据到引擎中间会执行的方法。
参数:
- request:request 对象
- response:被处理的
- response 对象
- spider:spider 对象
返回值可能会返回如下几种:
- 返回 Response 对象,会将这个新的 response 对象传给其他中间件,最终传给爬虫
- 返回 Request 对象:下载器链被切断,返回的 request 会重新被下载器调度下载。
- 如果其抛出一个 IgnoreRequest 异常,则调用request的errback(Request.errback)。如果没有代码处理抛出的异常,则该异常被忽略且不记录(不同于其他异常那样)。
process_exception(request, exception, spider)
当下载处理模块或process_request()抛出一个异常(包括IgnoreRequest异常)时,该方法被调用
返回值返回以下之一: 返回 None 、 一个 Response 对象、或者一个 Request 对象。
- 返回 None ,Scrapy将会继续处理该异常,接着调用已安装的其他中间件的 process_exception() 方法,直到所有中间件都被调用完毕,则调用默认的异常处理。
- 返回Response 对象,则已安装的中间件链的 process_response() 方法被调用。Scrapy将不会调用任何其他中间件的 process_exception() 方法。
- 返回 Request 对象, 则返回的request将会被重新调用下载。这将停止中间件的 process_exception() 方法执行,就如返回一个response的那样。
通常返回None,它会一直处理异常
from_crawler(cls, crawler)
这个类方法通常是访问settings和signals的入口函数
@classmethod
def from_crawler(cls, crawler):
return cls(
mysql_host = crawler.settings.get('MYSQL_HOST'),
mysql_db = crawler.settings.get('MYSQL_DB'),
mysql_user = crawler.settings.get('MYSQL_USER'),
mysql_pw = crawler.settings.get('MYSQL_PW')
)
爬虫中间件
Spider Middleware是介入到Scrapy的Spider处理机制的钩子框架。如图
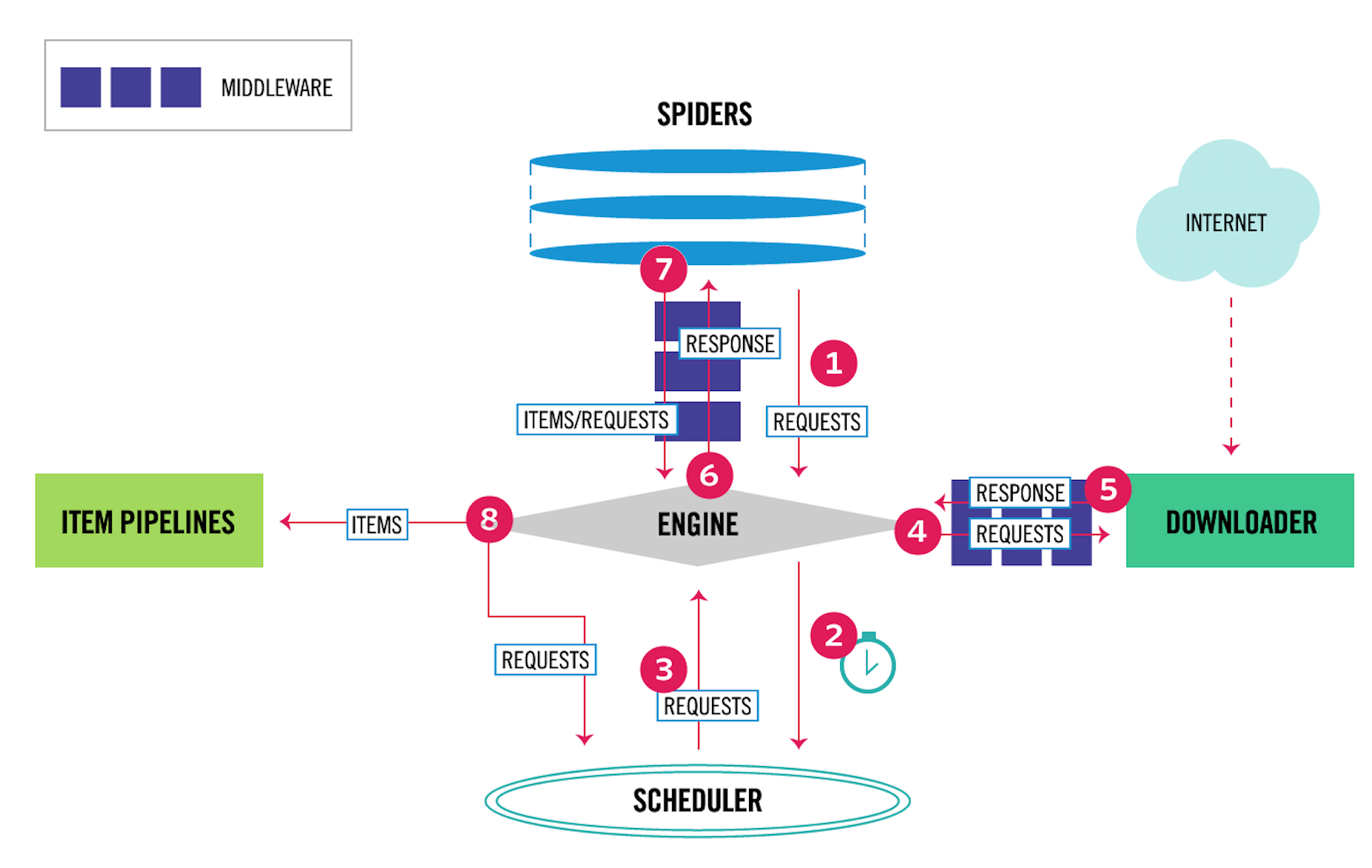 其中,4、5表示下载器中间件,6、7表示爬虫中间件。爬虫中间件会在以下几种情况被调用。
其中,4、5表示下载器中间件,6、7表示爬虫中间件。爬虫中间件会在以下几种情况被调用。
- 当运行到
yield scrapy.Request()或者yield item的时候,爬虫中间件的process_spider_output()方法被调用。 - 当爬虫本身的代码出现了
Exception的时候,爬虫中间件的process_spider_exception()方法被调用。 - 当爬虫里面的某一个回调函数
parse_xxx()被调用之前,爬虫中间件的process_spider_input()方法被调用。 - 当运行到
start_requests()的时候,爬虫中间件的process_start_requests()方法被调用。
当Downloader生成Response之后,Response会被发送给Spider,在发送给Spider之前,Response会首先经过Spider Middleware处理,当Spider处理生成Item和Request之后,Item和Request还会经过Spider Middleware的处理。
Spider Middleware有如下三个作用:
- 在Downloader生成的Response发送给Spider之前,也就是在Response发送给Spider之前对Response进行处理。
- 在Spider生成的Request发送给Scheduler之前,也就是在Request发送给Scheduler之前对Request进行处理。
- 在Spider生成的Item发送给Item Pipeline之前,也就是在Item发送给Item Pipeline之前对Item进行处理。
需要说明的是,Scrapy其实已经自带了了许多Spider Middleware,它们被SPIDER_MIDDLEWARES_BASE这个变量所定义。
SPIDER_MIDDLEWARES_BASE变量的内容如下:
'scrapy.spidermiddlewares.httperror.HttpErrorMiddleware': 50,
'scrapy.spidermiddlewares.offsite.OffsiteMiddleware': 500,
'scrapy.spidermiddlewares.referer.RefererMiddleware': 700,
'scrapy.spidermiddlewares.urllength.UrllengthMiddleware': 800,
'scrapy.spidermiddlewares.depth.DepthMiddleware': 900,
和Downloader Middleware一样,Spider Middleware首先加入到SPIDER_MIDDLEWARES设置中,该设置会和Scrapy中SPIDER_MIDDLEWARES_BASE定义的Spider Middleware合并。然后根据键值的数字优先级排序,得到一个有序列表。第一个Middleware是最靠近引擎的,最后一个Middleware是最靠近Spider的。
Scrapy内置的Spider Middleware为Scrapy提供了基础的功能。如果我们想要扩展其功能,只需要实现某几个方法即可。每个Spider Middleware都定义了以下一个或多个方法的类,核心方法有如下4个:
process_spider_input(response, spider)
当Response被Spider Middleware处理时,process_spider_input()方法被调用。参数有如下两个:response是被处理的Response对象。另一个是该Response对应的Spider。返回结果是:None或者抛出一个异常。
process_spider_output(response, result, spider)
当Spider处理Response返回结果时,process_spider_output()方法被调用。参数有如下三个:
response,是Response对象,即生成该输出的Response。result,包含Request或Item对象的可迭代对象,即Spider返回的结果。spider,是Spider对象,即其结果对应的Spider
必须返回包含Request或Item对象的可迭代对象
process_spider_exception(response, exception, spider)
当Spider或Spider Middleware的process_spider_input()方法抛出异常时,process_spider_exception()方法被调用。返回值是要么返回None,要么返回一个包含Response或Item对象的可迭代对象
process_start_requests(start_requests, spider)
process_start_requests()方法以Spider启动的Request为参数被调用,执行的过程类似于process_spider_output(),只不过它没有相关联的Response,并且必须返回Request。
